

Reasoning Models vs. Fast Models: The Emerging Split in AI Architecture
The era of judging an AI model solely by its tokens-per-second is officially over. For years, tech giants played a predictable game of speed-demon metrics, optimizing their algorithms to ensure that users got immediate, sub-second responses. It was a race for rapid-fire execution. Today, however, the industry is waking up to a new reality: speed is useless without substance, and the market is pivoting from fast answers to correct ones.
But as the limitations of standard Large Language Models (LLMs) became clear, the industry hit a wall. Fast models are great at summarizing emails or writing generic copy, but they fail catastrophically at complex math, advanced coding, and multi-step logic. They suffer from what psychologists call "System 1" thinking—fast, instinctive, and prone to making things up.
This realization has triggered a massive architectural schism in Silicon Valley. We are no longer chasing one giant, all-knowing model. Instead, the tech world is splitting into two distinct camps: Reasoning Models and Fast Models.
Here is a breakdown of this emerging architectural split and how it is redefining the future of software.
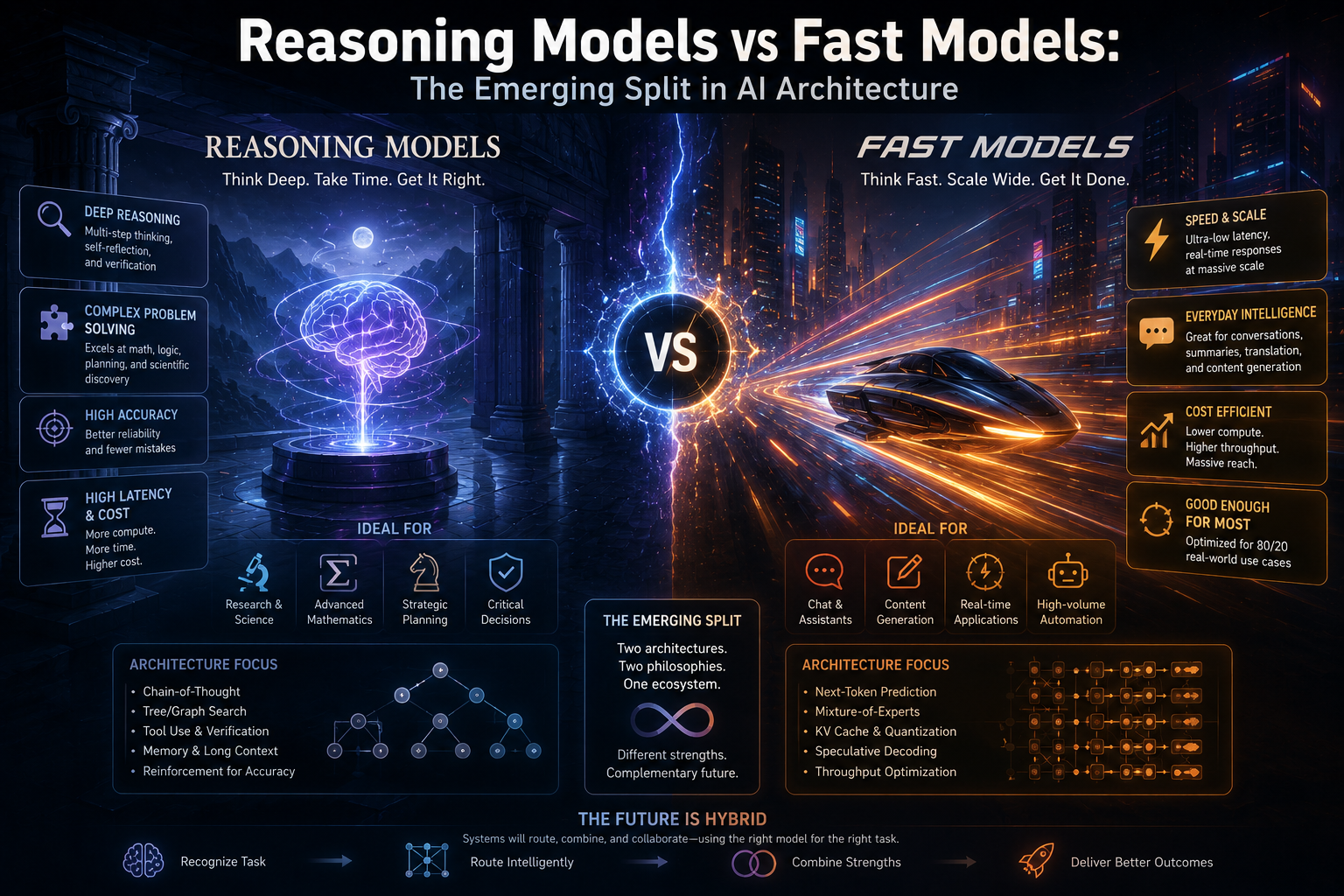
The Cognitive Split: System 1 vs. System 2
To understand this architectural shift, it helps to look at human psychology. Nobel laureate Daniel Kahneman famously categorized human thought into two systems:
System 1 (Fast Thinking): Fast, automatic, frequent, emotional, and subconscious. (e.g., Complete the phrase: "bread and...")
System 2 (Slow Thinking): Slow, effortful, infrequent, logical, and calculating. (e.g., Calculate $17 \times 24$ in your head.)
Until recently, AI models were purely System 1. They didn't "think" about an answer before typing it; they simply guessed the next most statistically likely word in milliseconds.
The new breed of architecture explicitly separates these two cognitive tracks.
Camp 1: The Fast Models (The Scaled-Down Speedsters)
Examples: Gemini Flash, Claude Haiku, GPT-4o
Fast models are engineered for hyper-low latency, massive throughput, and rock-bottom cost. They rely heavily on massive pattern recognition.
Key Characteristics:
Single-Pass Inference: The user sends a prompt, the model processes it in a single mathematical pass, and it immediately spits out the answer.
Heuristic-Driven: They don't problem-solve from scratch; they match your request against the trillions of patterns they memorized during training.
The Use Case: Perfect for real-time applications. Chatbots, customer support, transcription, quick content generation, and UI/UX interactions where a two-second delay feels like an eternity.
Camp 2: The Reasoning Models (The Deliberate Thinkers)
Examples: OpenAI o1/o3, DeepSeek R1, Claude Thinking
Reasoning models are built to do something radically different: they intentionally slow down and use Test-Time Compute. This means the model generates an internal, invisible "chain of thought" before it gives you the final answer. It drafts an idea, catches its own mistakes, refines its logic, and only shows you the result once it's confident.
Key Characteristics:
Multi-Stage Inference: The model explores multiple reasoning paths, cross-checks its logic against internal rules, and self-corrects mid-computation.
Compute Scalability: The more time and computational power you give a reasoning model to "think," the more accurate its answer becomes.
The Use Case: High-stakes, zero-error environments. Novel scientific research, complex software debugging, legal contract analysis, and solving dense financial algorithms.
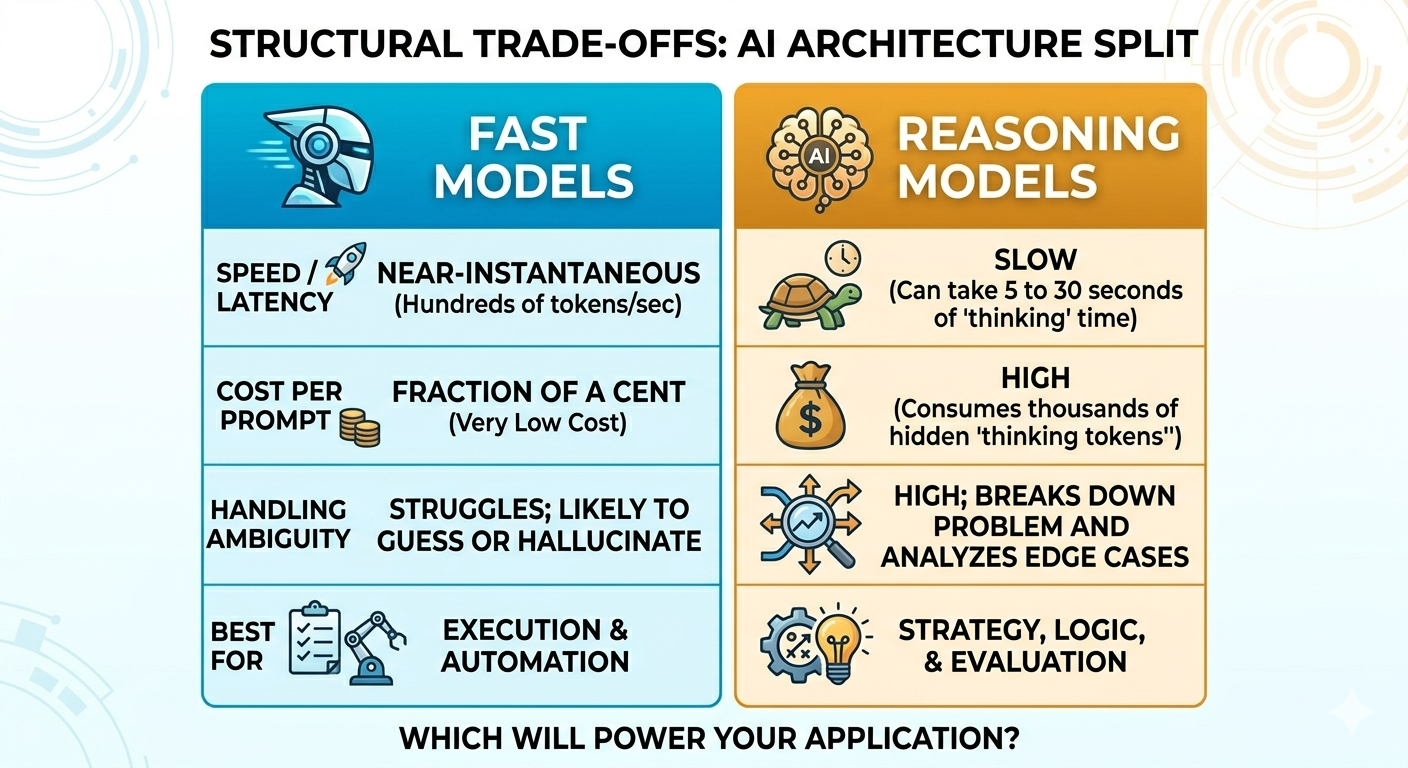
The Structural Trade-Offs
This split has forced developers to make a deliberate choice between two entirely different trade-offs:
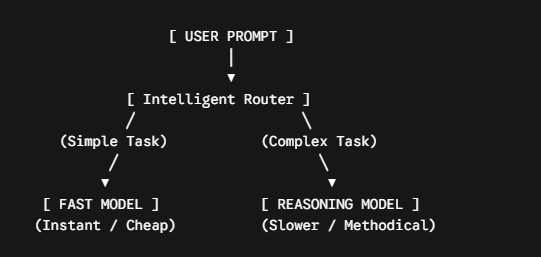
The Future Is Hybrid: Tiered Orchestration
The industry is rapidly realizing that defaulting to a heavy reasoning model for everything is an economic nightmare—you don’t need a PhD-level reasoning model to fix a spelling mistake in an email. Conversely, using a fast model to design a banking architecture is incredibly risky.
The winning architecture of tomorrow isn't one or the other; it’s an orchestration layer.
Modern AI systems are being built with automated routers. When a user submits a prompt, a lightweight, fast model evaluates it. If the request is simple ("Write a Tweet about coffee"), the fast model handles it instantly. If the request is identified as highly complex ("Find the memory leak in this 500-line Python script"), the system automatically escalates the task to a deep-thinking reasoning model.
The Bottom Line
The narrative that AI is a single, monolithic entity getting universally "smarter" is dead. The future of AI architecture is fit-for-purpose specialization.
By dividing the workload between the lightning-fast executors and the deep-thinking analysts, the tech world is finally building AI systems that don't just mimic human output—they mirror the dual-nature of human intelligence itself.
Are you building with AI? Do your applications value raw speed, or are you willing to wait 10 seconds for a flawless, deeply reasoned answer? Let’s debate in the comments!
Tags
#AIArchitecture #ReasoningModels #FastModels #MachineLearning #System1System2 #TechTrends #LLMs #OpenAIo1 #DeepLearning #SoftwareEngineering #TechStrategy #InferenceCompute #AIInfrastructure #FutureOfAI #System2Thinking #TestTimeCompute #AIOptimization #LLMArchitecture #TechDisruption #Developers #ArtificialIntelligence #AITrends2026 #ComputeScaling #SmartRouting #ComputerScience #DeepSeekR1 #OpenAIo3 #EnterpriseAI #TechStrategy