

Low-Precision Computing (FP4/FP6) and Its Impact on Model Efficiency
Artificial intelligence in 2026 is no longer constrained primarily by algorithmic innovation. The bottleneck has shifted to compute economics, memory bandwidth, and energy efficiency. In this environment, low-precision arithmetic—particularly FP4 and FP6—has emerged as one of the most consequential technical shifts in modern AI systems.
This article examines what FP4/FP6 actually are, why they matter, how they affect training and inference, and what they mean for hardware roadmaps from companies like NVIDIA and AMD.
1. From FP32 to FP4: The Precision Compression Timeline
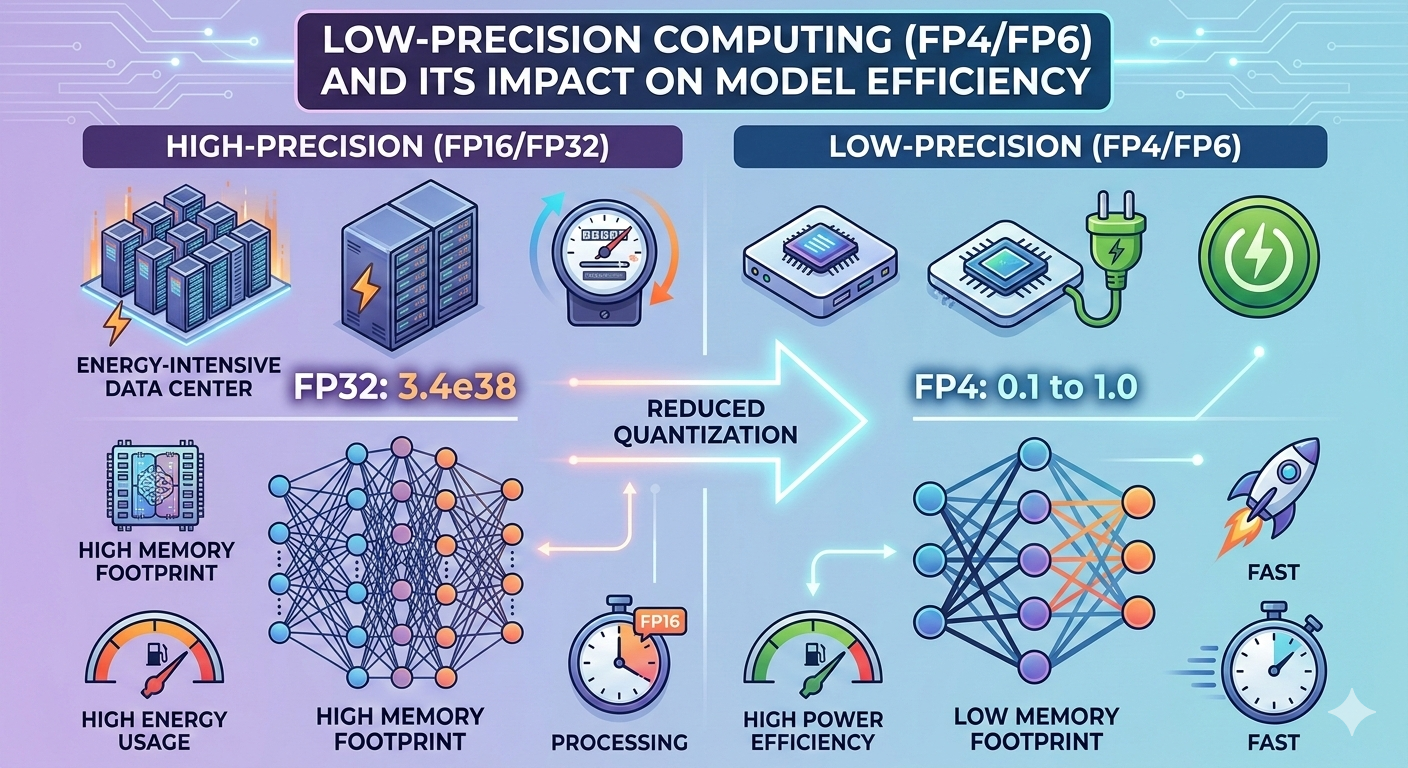
Floating-point formats define how numbers are represented in hardware. Historically:
FP32 → Standard for scientific computing
FP16 / BF16 → Enabled large-scale deep learning
FP8 → Major breakthrough for efficient training (2023–2024 era)
FP4 / FP6 → Emerging formats for ultra-efficient inference and selective training workloads
Reducing precision decreases:
Memory footprint
Bandwidth requirements
Energy per operation
Silicon area per arithmetic unit
The key question is no longer “Can we reduce precision?” but rather “How low can we go without destabilizing learning?”
2. What Are FP4 and FP6?
FP6 (6-bit floating point)
More expressive than FP4
Often structured with limited exponent bits and small mantissa
Suitable for:
Efficient inference
Fine-tuned model adaptation
Some training workloads with calibration
FP4 (4-bit floating point)
Extremely compact representation
Typically used with:
Post-training quantization
Inference-only deployments
Weight-only quantization schemes
FP4 is not just “smaller FP8.” It requires:
Careful scaling strategies
Per-channel normalization
Advanced quantization-aware training
Without these techniques, gradient instability and representational collapse occur quickly.
3. Why Precision Matters More Than FLOPS in 2026
In frontier AI systems, the dominant constraint is often memory bandwidth, not raw arithmetic throughput.
Lower precision reduces:
Model size in VRAM
Activation memory footprint
Interconnect bandwidth requirements
This creates cascading benefits:
Higher throughput per GPU
Reduced latency in serving clusters
Lower cost per token
Better energy efficiency per inference
For hyperscale deployments, even a 20–30% efficiency gain translates into millions of dollars in infrastructure savings annually.
4. Training vs. Inference: Different Precision Regimes
Inference
FP4 and FP6 are increasingly viable for:
LLM inference
Vision transformer serving
Edge-device deployment
On-device generative AI
Modern quantization pipelines combine:
Calibration datasets
Outlier channel handling
Mixed-precision accumulators
Result: Near-FP16 quality at dramatically lower memory cost.
Training
Training is more sensitive to:
Gradient precision
Accumulation stability
Dynamic range
Hybrid strategies are common:
FP8 or FP6 for forward/backward passes
Higher precision accumulation (FP16/BF16)
Master weights stored at higher precision
Full FP4 training remains experimental but is under active research.
5. Hardware Implications
Low precision fundamentally reshapes chip design.
Arithmetic Density
Reducing bit-width increases:
Tensor core density
Compute per watt
Effective throughput
Memory Hierarchy Optimization
Lower precision:
Reduces HBM pressure
Improves cache utilization
Enables larger models per device
Chipmakers are now optimizing silicon explicitly for sub-8-bit arithmetic. Vendors such as NVIDIA and AMD are integrating native support for ultra-low precision tensor operations to remain competitive in large-scale inference markets.
6. The Economics of Low Precision
Precision reduction has become a strategic lever.
Hyperscaler Perspective
Lower cost per inference request
Higher GPU utilization
Reduced energy consumption
Extended hardware lifecycle
Enterprise AI Providers
Smaller serving clusters
More competitive pricing
Ability to deploy larger models within fixed hardware budgets
Low precision is not just a technical innovation—it is a margin optimization tool.
7. Risks and Technical Trade-Offs
Despite its benefits, low precision introduces challenges:
Numerical Instability
Accuracy Degradation
Outlier Sensitivity
Calibration Complexity
Toolchain Fragmentation
Mitigations include:
Mixed-precision training
Adaptive scaling
Per-layer precision tuning
Quantization-aware fine-tuning
The industry is shifting toward precision as a tunable parameter, not a fixed system constraint.
8. Edge AI and On-Device Acceleration
FP4/FP6 are particularly transformative for:
Smartphones
Autonomous systems
Robotics
IoT deployments
Lower precision allows:
Larger models on constrained memory devices
Faster inference at lower power
Always-on AI capabilities
As AI becomes embedded into consumer hardware, low precision becomes foundational rather than optional.
9. The Strategic Shift: Precision as Architecture
We are entering a phase where:
Model architecture
Hardware architecture
Numeric precision
are co-designed.
Future AI stacks will dynamically allocate precision:
High precision for sensitive layers
Low precision for bulk computation
Adaptive precision based on workload
Precision is becoming a systems-level optimization variable.
10. Outlook for 2026 and Beyond
Expect the following trends:
Wider native FP4 hardware acceleration
Automated precision optimization pipelines
Training stability improvements for ultra-low bit formats
Competitive differentiation in inference cost per token
The shift to FP4/FP6 is not incremental—it is structural. As models scale and deployment expands, low-precision computing will define the efficiency frontier of AI systems.
In 2026, the winners in AI are not just those with the largest models—but those who can run them with the highest computational efficiency.