

AI Memory Architectures in 2026: RAG vs. Long-Context Models
The debate that defined 2024 is over, and the winner is... both.
As we move through March 2026, the AI developer community has reached a sophisticated consensus on the "Memory Wars." Two years ago, the rise of Million-Token Context Windows (like those in Gemini 2.5 Pro and GPT-4.1) led many to predict the death of Retrieval-Augmented Generation (RAG). The logic was simple: "If I can fit the whole library in the prompt, why bother with a database?"
But as production-grade agents have hit the market, the reality has proven to be far more nuanced. In 2026, we don't choose between RAG and Long-Context; we orchestrate them.
The "Brute Force" Problem of Long Context
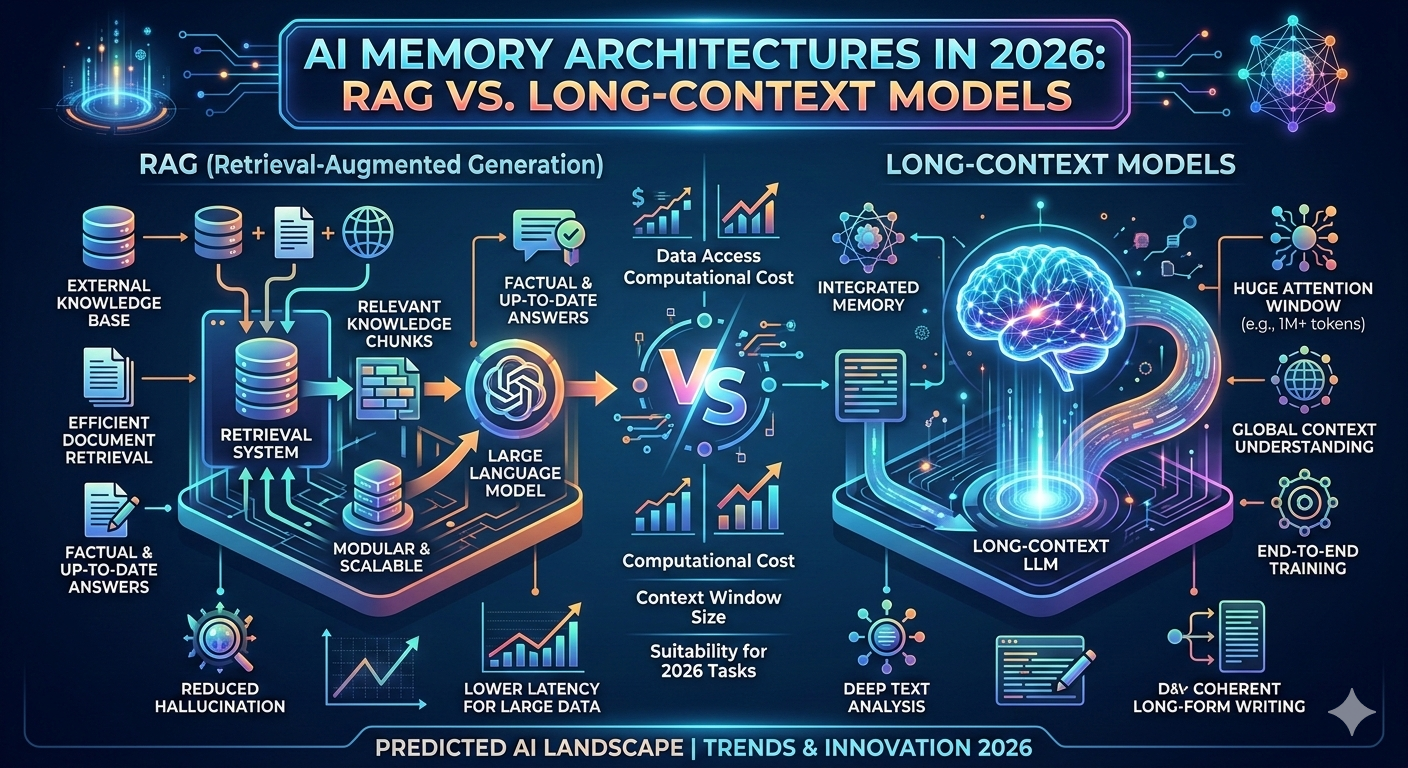
While models can technically "read" 1 million to 10 million tokens in a single pass, doing so every time is the computational equivalent of a "brute-force" attack.
The Cost Factor: Processing 1 million tokens for every single user query is 1250x more expensive than a targeted RAG call. For enterprise-scale applications, "dumping everything in the prompt" is a fast track to bankruptcy.
The Attention Deficit: Even in 2026, models still suffer from the "Lost in the Middle" phenomenon. When a model’s attention is spread across a massive context, the precision of its reasoning can degrade.
Latency: A million-token inference can take 30–60 seconds to "think," whereas a RAG-based response remains snappy at sub-2-second speeds.
Why RAG is Still the "Production Standard"
RAG has evolved from "mandatory plumbing" into an "optimization lever." In 2026, RAG is the go-to architecture for:
Dynamic Data: If your information changes every minute (stock prices, news, live logs), you cannot wait for a model to "re-read" a giant file. You need a vector database (like Pinecone or Milvus) to serve the freshest "chunks."
Auditability: RAG provides a clear "paper trail." In legal and medical AI, you need to see exactly which document a fact came from. Long-context models can be "black boxes" that make it harder to verify sources.
Privacy & Permissions: RAG allows for "Access Control Lists" (ACLs). You can ensure a user’s AI agent only retrieves the documents they have the rights to see—something nearly impossible to manage if you just feed a model a massive, unified knowledge base.
The 2026 Synthesis: "Self-Route" and Hybrid Memory
The most advanced systems today use a Hybrid Memory Architecture.
Modern agents use a "Router" to decide the best path. If a user asks a complex question about a 500-page legal contract, the system uses Long-Context to ensure no nuance is lost. If the user asks for a specific policy from a 50,000-document corporate handbook, the system uses RAG to find the needle in the haystack.
This is the era of Context Engineering. It’s no longer about how much a model can remember, but how intelligently we choose what it needs to know at any given second.